HSTS High Availability
We all know the story. You start with a single High Speed Transfer Server and a web app such as Shares or Faspex. It becomes widely popular and is used by everyone. Soon, your business cannot survive without it. This story is even more common with so many people working remotely these days.
Then it happens, and everything comes to a screeching halt. A hard disk fails, a power supply goes poof, or a mistyped command renders the machine unbootable. For these situations, people such as us like redundancy. This redundancy can include mirrored drives, dual power supplies, and regular backups (that have been tested, of course). For times when you cannot go down under any circumstances at all, we deploy multiple servers. These could be physical, virtual, containers or, pod. The goal is that if any one of these important aspects of your high speed file transferring systems vanishes, your productivity will not be out the door with it.
But, what if things were different. What if instead of having redundancies upon redundancies, and servers to back up servers, your organization had a process based on the Aspera connect plugin? In this scenario, high availability is as simple as keeping the configs identical between multiple HSTS machines and putting a load balancer in front.
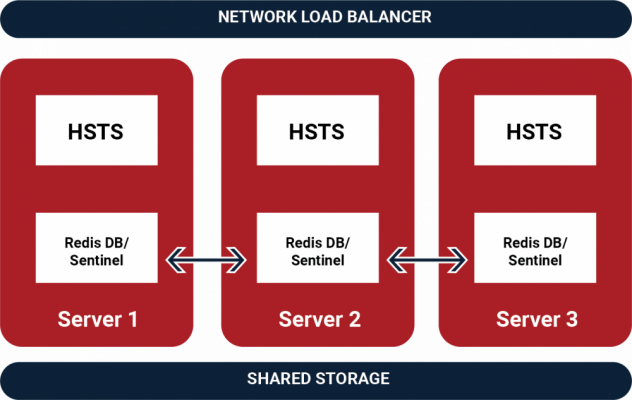
Enter the more robust world of Aspera’s NodeAPI based applications. So much can be done via this API. It’s a critical service that links the Aspera software suite together. In a highly-available environment, It does have one challenge that must be solved. The NodeAPI stores its run state in Redis, a memory based key value store. Each HSTS has its own Redis instance.
Problem:
- You start a transfer via NodeAPI and your load balancer directs the query to the first HSTS machine.
- You go to query the status of that transfer and the load balancer directs the query to the second HSTS machine.
- What you get back is an error that the transfer you are looking for does not exist.
Solution:
- Make all the HSTS nodes use the same Redis database. Now in the previous example, it matters not where you ask your status query because all nodes are recording their information in a common repository.
Learning More About Redis
If you want to know about the details of how Redis works, we highly recommend going directly to the HA Redis documentation site. To make a long story short, to make all the features of HSTS highly available, we need to implement HA Redis. HA Redis requires a minimum of three nodes. More nodes is okay as long as it is an odd number.
The default Linux HSTS install includes all the required components and documentation to make this work by yourself.
Contact Us if You Have Any Questions
May your servers always be up, your transfers always be fast, and don’t forget that we are here to help.